Project Overview
项目介绍
第5组本次实训完成了两个 Python 爬虫程序,并将结果整理为可下载、可查看、可演示的静态网站。页面结构按汇报使用场景组织,便于老师快速了解项目目标、实现方式和最终成果。
任务一
小说爬虫
自动访问小说目录页和章节页,提取章节标题、正文内容,保存文本文件,并生成章节字数与高频词统计图。
任务二
百度图片爬虫
根据关键词批量搜索图片,提取图片链接并下载保存,支持去重、格式识别、异常处理和 GUI 图形界面。
展示方式
静态网站汇总
将 PPT、源码、统计图和图片结果统一托管到 Cloudflare Pages,形成一个便于访问和提交的项目展示站。
Presentation
PPT下载
汇报材料提供新版 PPTX 和兼容版 PPT,适合在不同版本 PowerPoint 或 WPS 中打开。
Source Code
源码下载
两个爬虫均整理为单文件 Python 程序,便于提交、检查和独立运行。
Results
成果展示
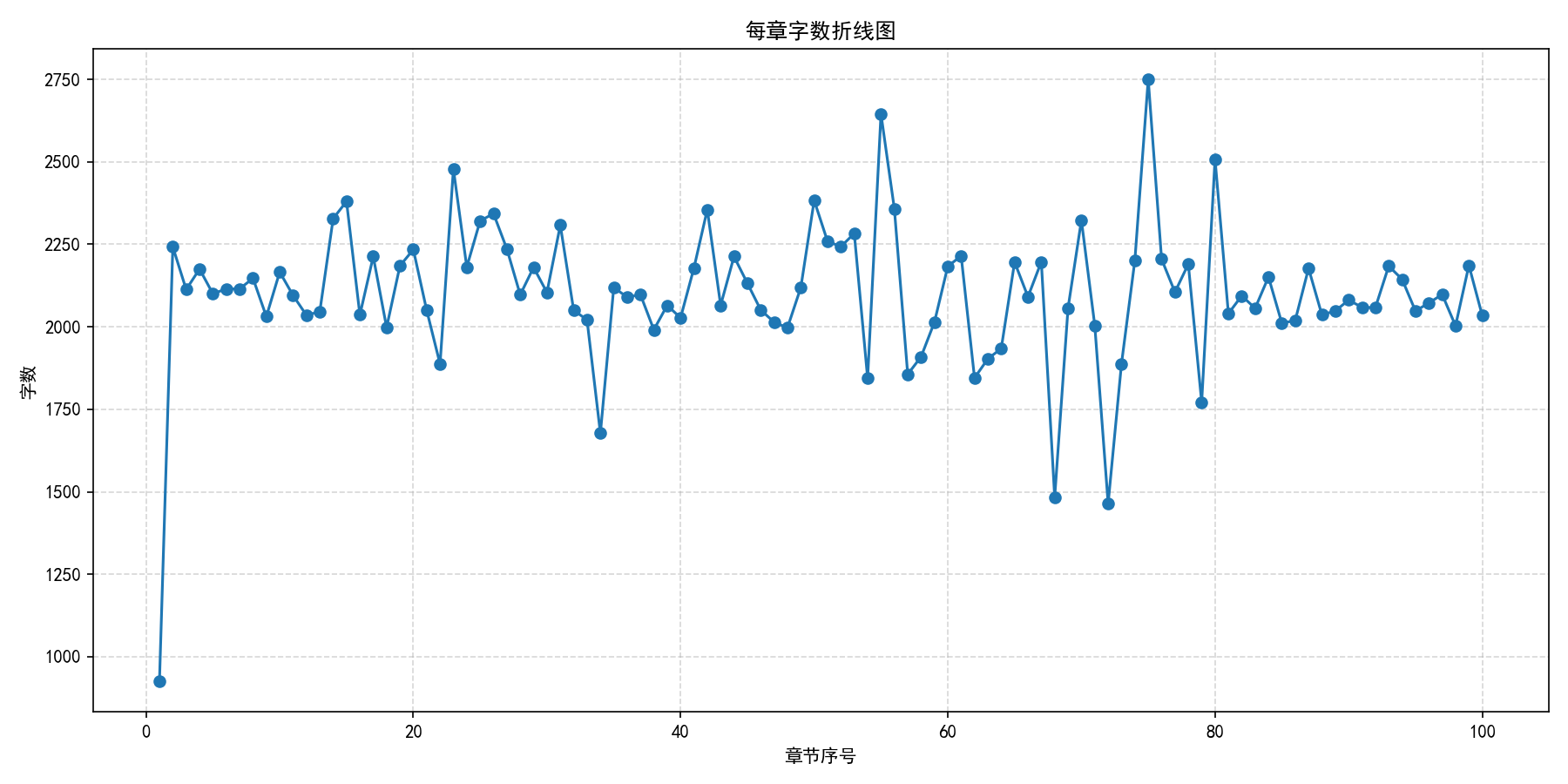
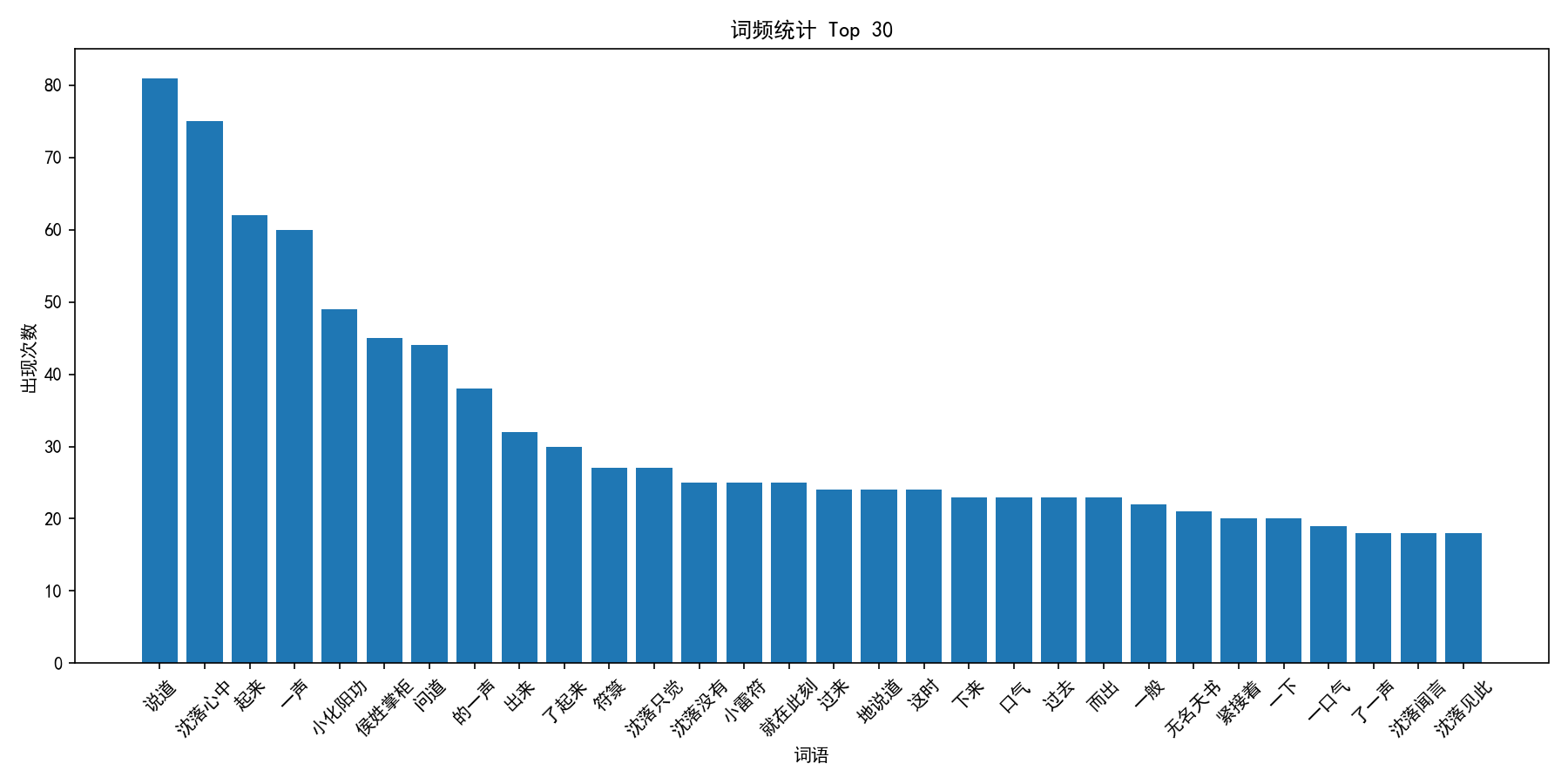
以下为小说爬虫生成的统计图,以及百度图片爬虫下载得到的示例图片结果。
小说爬虫统计结果
通过章节字数和词频图,可以直观看到文本数据的规模和高频关键词。
百度图片爬取结果
示例图片来自关键词搜索结果,展示图片采集、保存和结果整理效果。





Review
问题与总结
项目实现过程中重点解决了网页结构变化、反爬限制、图片链接失效和文件兼容性等实际问题。
遇到的问题
- 部分网页存在基础反爬限制,请求过快容易失败。
- 小说章节页结构不完全统一,需要兼容不同正文容器。
- 图片链接可能重复、失效,图片格式也不固定。
- 不同电脑的网络代理设置会影响爬虫请求结果。
解决方法
- 添加 User-Agent、Referer、请求间隔和失败重试。
- 使用多个解析规则,提高章节正文提取成功率。
- 通过文件头识别图片格式,并使用哈希值去重。
- 提供自动、直连、系统代理和自定义代理模式。
实训收获
- 掌握请求、解析、清洗、保存、统计和展示的完整流程。
- 熟悉 requests、BeautifulSoup、pandas、matplotlib 等工具。
- 提升了调试网络问题、整理成果和项目展示的能力。
- 将零散文件整理为可在线访问的完整项目页面。